【セミナーレポート】情報革命を終わらせるために〜独自LLMの開発とその展望〜
本記事はnoteに記載したものを転載しています。
2024年1月30日に開催されたLightblue主催のウェビナー「情報革命を終わらせるために〜独自LLMの開発とその展望〜」のセミナー内容をお伝えします。Lightblueでは、独自のLLMモデル開発を行っており、商用利用可能な日本語LLM「Karasu」「Qarasu」を公開いたしました(プレスリリースはこちら)。本セミナーでは、自社でのLLM構築やAI活用を検討している企業様に対して、汎用AI・生成AIをどのような形で実装していくか、ご紹介します。
登壇者
園田 亜斗夢
株式会社Lightblue 代表取締役
東京大学工学部卒業、東京大学大学院工学系研究科在学。AIの社会実装、レコメンダーシステムの研究を行う。2018年にLightblueを設立。
Peter Devine
株式会社Lightblue 自然言語処理研究員
オークランド大学院工学部、UCL大学院卒業。
LightblueではKarasu/QarasuなどLLMの開発に従事。
目次
情報革命を終わらせるために〜独自LLMに取り組む理由〜
Lightblueは、東京大学の鳥海教授の研究室からスピンアウトする形で2018年に創業した会社です。事業としては、本日のテーマである自然言語処理と、人にフォーカスした映像解析(Human Sensing)の二つに取り組んでいます。
Human Sensingは、工場の作業工程の見える化や工事現場の安全管理などの実績があります。言語処理領域に関しては、まさにChatGPTがフィーチャーされていますがLLM(Large Language Model)の先駆けとされるようなモデルの日本語学習から取り組んできました。
そのような中で、2023年の12月に事前学習とファインチューニングを行った日本語のLLMモデルを公開しました。本モデルの詳細については、後ほど詳しくご紹介します。
理系東大生でもChatGPTを日常的に使う学生はわずか3割
ところで、皆さんはChatGPTを日常的に使っていますか?
2023年の春、GPT4がリリースされた後に「大学生は勉強しなくなるのでは?」、「これからの人材はLLMの台頭によってどのような能力が必要なのか?」などの議論が盛んになったことは、記憶に新しいかと思います。そんな文脈で東大の先生方も、産業革命に匹敵する発明であるとか、学生はChatGPTとどう向き合うべきかといった発信をされていました。
一方で、2023年4月時点では、私がお手伝いしている東京大学の情報系の研究室で、大学3年生向けの講義内におけるChatGPTを触ったことがある学生の割合というのが全体のわずか3割ほどに止まりました。
生成AI登場「産業革命に匹敵」 太田・東大副学長に聞く – 日本経済新聞米オープンAIの「ChatGPT(チャットGPT)」などの生成人工知能(AI)について、東京大学は学生・教員に「傍観せず、www.nikkei.com
ChatGPTは万能ツールではなく「賢い新卒」
ChatGPTがフィーチャーされた要因は、誰もが無料で使えるという環境が最も大きいと考えられていますが、技術的にどのような変化がもたらされたのかを改めて再確認しましょう。
GPT3からChatGPTへの変化の過程では、人のフィードバックを基にした強化学習で、「有用で無害な出力」が実現できるようになった点が特徴です。人間のフィードバックがもたらす効果として、一部においては論理より倫理が優先され、強いフィードバックがかかりすぎている可能性が示唆されてます。

それでは実際に普段の業務の中でLLMをどのように捉えて活用するべきかというと、私たちは「賢い新卒」として使うことを推奨しています。
ChatGPTのWebサイトにアクセスすると文章作成が優れていたり、議事録をそれなりの精度で要約したりと、なんとなく使えそうなアウトプットが得られます。

一方、入出力量の制限や、ハルシネーションと呼ばれる事実関係が不明確な内容でも何となくそれらしい答えを出力してしまう事象、または処理の速度など、業務フローに組み込む上では依然として高いハードルがあります。
各社独自のデータに基づいた回答ができるLLMをどう実現していくのか。一般的に①プロンプトに情報を入れる(どのようなデータを用いて作業を実行するか)②Fine tuning(異なるデータセットを使用した再トレーニング)③Embedding+Vector Store(テキストデータを数値データに変換し、保存・検索する)という3つの手法を用いてLLM活用が検討されていると言われています。
自社独自のデータを使えるようになると、実運用ができる状態が目指せるようになるのかなと考えています。
LLM開発の現実〜1000万円以上無駄にした経験から学ぶ〜
LLM開発にはGPUと電力消費の大きなコストがかかってしまう
私たちは日々自然言語処理のソリューションを様々なサービスとして提供していますが、開発リソースとして、高性能なGPUが何十台、何百台も必要です。NVIDIAのA100・H100というGPUがよく使われるのですが、そもそもGPUのプロセッサー自体が品薄と言うこともありますが高額かつ電力の消費量も大きく、膨大なコストがかかります。
環境への負荷も無視できず、最近の論文ではカーボンニュートラルの取り組みはもちろん、どのような発電方法の電気を何時間使用し、どれほどのエネルギー消費をしたかと言う記録まで発表されるようになりました。

Lightblueが公開しているLLMは、1つ約200万円ほどのコストで開発されます。一方で、開発に際してのデータセットの整備や試行錯誤などの部分でトータル約1000万円のコストがかかってしまった実体験を共有できればと思います。
クラウドでA100インスタンスを使う際に、メモリサイズが40GBか80GBか、GPUのボード数とメモリの組み合わせによって様々なタイプのインスタンスが用意されています。昨今、どのベンダーもA100インスタンスのリソースは枯渇しており、クラウド従来の「使いたいときに必要なだけインスタンスが使える」仕組みから、「計画的に予約して使う」仕組みに変化しています。
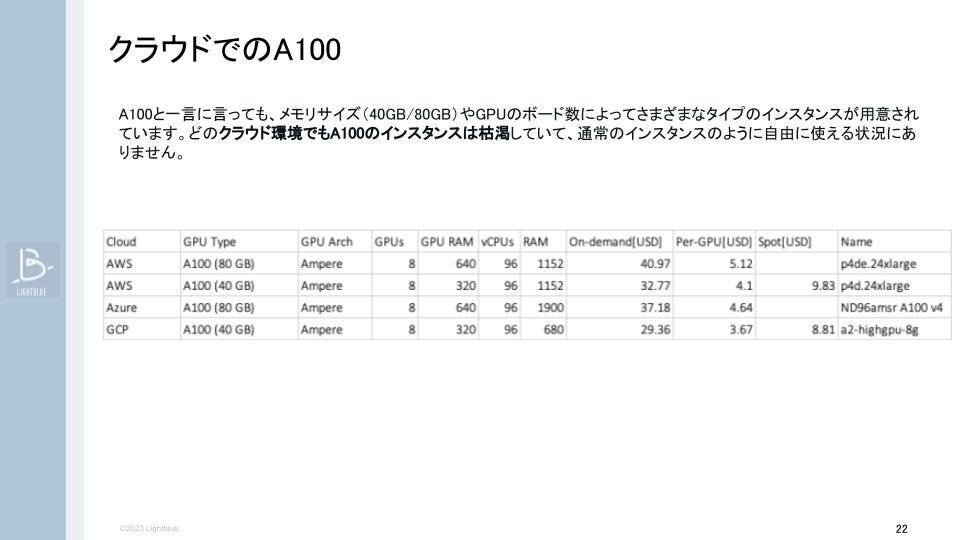
1つ目の落とし穴は「予約機能」でした。80GBのインスタンスは事前に割り当てを申請し、承認後すぐにインスタンスを起動させるか『予約機能』を使う必要があります。
ただし、この予約機能は名前と異なり、インスタンスの起動と同等のコストがかかります。
今回1000万円を無駄にしてしまった背景として、申請ルールや料金面、実験計画などをチーム内で認識を揃えていなかったことが挙げられます。例えば、B (billion)、M (million)、K (kilo)といった数字の単位に馴染みがなく、さらに全ての金額がドル換算になることで簡単なはずの計算が複雑になってしまいました。
実は、モデルの学習にA100 80GBは不要ということが検証を重ねるうちに判明しました。A100 40GBで学習をさせると、約30%ほど低いコストでインスタンスを立てることが可能となります。
最終的には、試行錯誤を重ねながら、事前の計画を丁寧に立てることで、予算の範囲内で適切な学習を行うことも可能となりました。
結論として、LLM(Large Language Models)の事前学習とファインチューニングは、特定のタスクに特化することで十分な性能を発揮しました。このアプローチは、セキュリティやコストの観点からも選択肢になり得ると考えられます。
この難しさと効果のバランスを考慮しながら、今後もLLMの開発にコミットしていく意向です。APIで実現できないことや、APIよりも高い性能を求めるためだけでなく、開発イベントで指摘されているように、LLMの最適化は非常に難しいとの認識があります。

日々、世界中でLLMサービスが生まれる昨今ですが、LLMの真の意味での活用のためにはAPIの利用だけでなく、本質的な理解が求められると指摘されています。新しい技術にばかり気を取られてしまうことなく、LightblueはLLMの独自の研究開発に今後も手を動かし続けてコミットして行きたいと考えています。
Karasu/Qarasuの特徴〜開発エンジニアPeterによる解説〜
お客様にとってより使いやすいLLMモデルを開発するためのKPI
Lightblueが公開しているLLMモデルKarasu/Qarasuの開発に取り組んでいます。ピーターと申します。Karasu/Qarasuの開発についてローカルでの大規模LLMの開発ノウハウを共有したいと思います。
はじめに、私たちLightblueの目標は、様々なお客様がお持ちの多様なビジネスに対して活用いただけるようなLLMを開発することです。そのためには困難な目標を設定し、達成するためのKPI設計が必要でした。
先ほど園田さんが申し上げたように、LLM開発には様々な評価方法がありますが、Karasu/Qarasuの評価において私達がKPIとして定めた評価方法はMT-Benchでした。
MT-Benchは80件のプロンプトを使ってLLMに質問し、出力結果をGPT-4と比較して評価されるものです。

MT-Benchに含まれるプロンプトは実際に人間が聞きそうな質問です。そのため、数学、歴史的、さらにはクリエイティブな作文の問題や仕事で使えそうなプロンプトまでを網羅しています。Karasu/Qarasuは、幅広いジャンルのプロンプトに対して高精度のアウトプットを出すことを目指して開発しています。
開発が始まる前に、アプローチ法や日本国内のLLMを評価していました。初めは多くのLLMがゼロベースから事前学習をしていて、ランダムな重みから学習を開始していましたが、開発難易度が非常に高く、ChatGPTと同等の精度を得るためには数億円のコストが必要です。
そのためLightblueでは、既存モデルに対して追加学習のアプローチが適していると考えました。

ファインチューニングは事前学習と比較した際に、微調整のような位置付けとなります。LLMの指示データを使って学習させるため、総合知識のアップデートではなくアウトプットの方法などを学習させられます。
LLMの開発においてデータセットは非常に大事なものですが、日本語のオープンソースのデータセットは高品質とは言い難いテキストや教師データが多いと感じます。
追加学習とファインチューニングデータの改善アプローチで、私達がKarasu/Qarasuを開発しました。開発のはじめに、ファインチューニングのデータセットを作成する必要がありました。様々な工夫を施して、非常にデータ量が重く、開発費が高額で実運用に耐えないモデルから、10万件のファインチューニングのデータセットを作成してモデルの微調整を行いました。
様々なお客がRAG(Retrieval Augmented Generation:参照したドキュメントに基づいてレスポンスするもの)、特に社内ドキュメントなどと参照するニーズが大きく、RAGに関するデータセットも作成しました。

高いMPベンチスコアが既にあったので、モデルのブラッシュアップに取り組みました。この時のコストは16x A100 40GBのインスタンスで60時間ですので、数百万円程度になります。
再チューニング時はデータの質は問題ありませんでしたが、量が少なく外注に依頼する時間が早かったです。結果はKarasu/QarasuがMT-Benchのスコアを獲得し、国内のオープンソースモデルのLLMの中で最も優れたものであると評価されました

イギリスとフランスのオープンソースのモデルで性能が高いものがありますが、これらは何枚のGPUで回す必要があり、コスト的にGPT3.5より高くなります。
今後、LLM開発で取り組みたいことはたくさんあります。直近だと論理的な問題で学習をさせることで理解させたいと考えています。
GPT-4 が解けないなぞなぞ、「日本からもアメリカからも中国からもオーストラリアからも南アフリカからもだいたい同じ距離の場所はどこ?」というものがあります。
みなさんからは「太平洋の真ん中」などの答えが多く上がりましたが、答えは「地球のコア」というなぞなぞです。このように、当たり前ではない切り口を与えて学習させることで、よりアウトプットが上がるという仮説があります。これらの観点を今後の開発に含めたいと思います。
他にも、ハルシネーションが起こらないように学習させたいと思います。今は特にRAGでは、改善はこれからで、参照のドキュメントがなくてもハルシネーションしないように学習させたいです。
最後の2点はエージェント機能の追加です。幅広い管理ができるようになればと考えています。長期的に見ると、マルチモーダルの機能実装を目指しています。
でもまだ一番何か優れてるマルチモーダルのモデルも役に立つ場所がちょっと限られてるように思ってますので、研究をフォローして、良い感じになりましたらKarasu/Qarasuに含めたいと考えています。
まとめ
園田:
LLMはどのモデルが最適なのかという問いにおいて、単一的に評価できるものではないということは私たちが一番実感しています。80%から90%のユースケースにおいてはGPTでカバーできると考えています。
一方で、フォーマットを全社で揃える場合や、セキュアな環境を使いたいというニーズに対しては、どのような情報をGPTのAPIに入れていいのかを都度慎重に検討することにかなり労力を使ってしまうので、独自環境構築の必要性が生まれてくるでしょう。
LLMを使ってやりたいことを実現するために、必要な知識をどれくらい学習させる必要があるか、求めるゴール感を調整しながら一緒に開発を進めていければと考えています。
まずは現場の課題を洗い出すためのワークショップもLightblueで提供しています。生成AI活用の第一歩としてご相談をいただけますと幸いです。
本日はセミナーにご参加くださりありがとうございました。
Lightblueでは、定期的にセミナーを実施しています
技術トレンドや事例紹介、新製品のご案内など、Lightblueでは毎月、異なるテーマでウェビナーを実施しています。ぜひ同僚の方やクライアント様とお誘い合わせの上、ご参加ください。